|
Uncertainty Dampening: Correcting the Q-Landscape in Offline Reinforcement Learning. Under review.
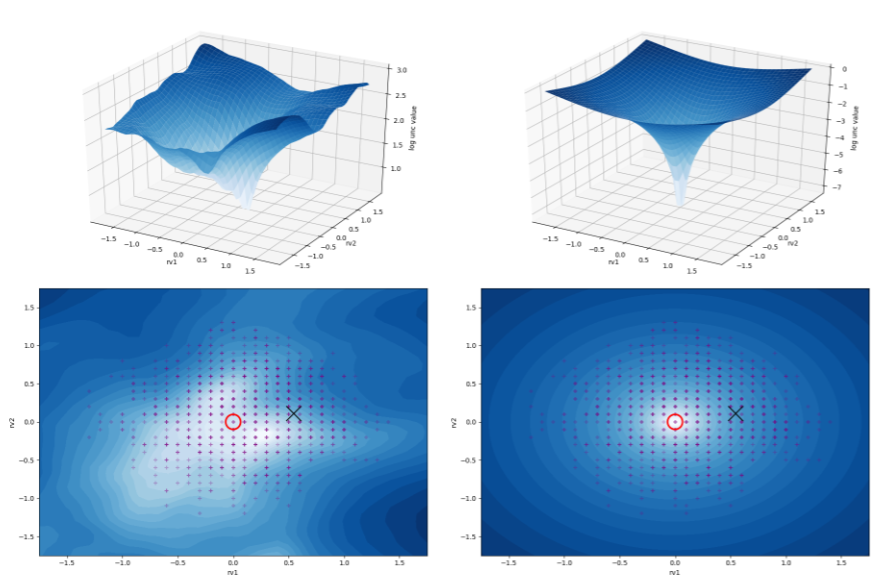
In this research, we use landscape visualization to bring a better understanding to the problems of offline reinforcement learning and show how different policy constraints can affect offline algorithms such as BCQ. We also use these visualizations to find a good uncertainty estimator, and use it in our new method which helps correct the Q landscape directly. |
|
Randomized Ensembled Double Q-Learning: Learning Fast Without a Model. Xinyue Chen, Che Wang, Zijian Zhou, Keith Ross. ICLR 2021.
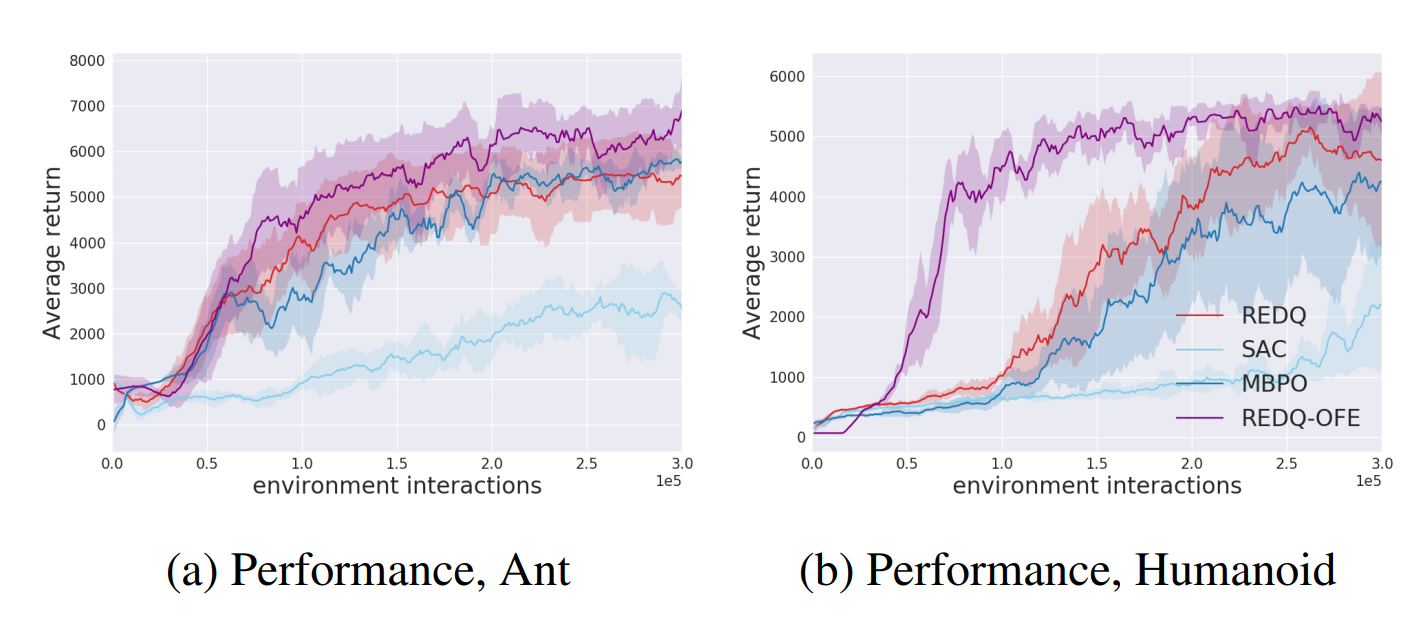
In the continuous action space benchmarks such as MuJoCo, why do we typically see an update-to-data (UTD) ratio of 1? What is stopping us from taking more mini-batch updates? In this paper, we present extensive studies that reveal why a high UTD can be harmful, and show how a high UTD can be utilized for performance improvement. Our model-free method Randomized Ensembled Double Q-Learning (REDQ) achieves a massive 7x sample efficiency improvement over Soft Actor-Critic on the most difficult environments. |
|
BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning, Xinyue Chen, Zijian Zhou, Zheng Wang, Che Wang, Yanqiu Wu, Keith Ross. NeurIPS 2020.
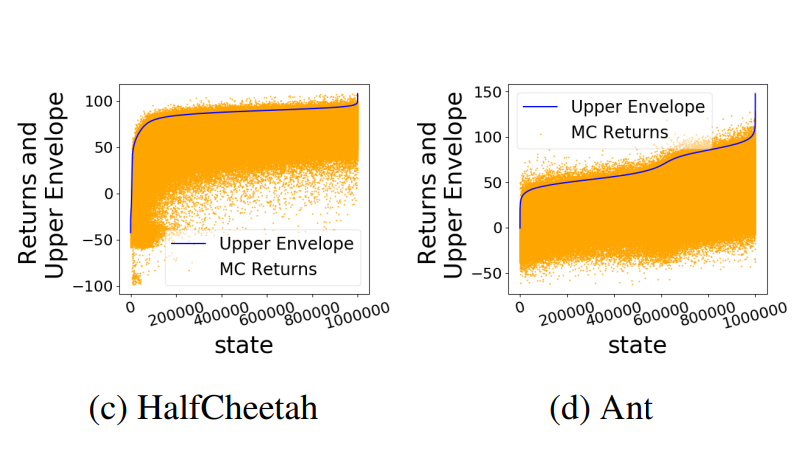
In this paper we propose an advanced imitation learning method for batch deep reinforcement learning. Our method, Best-Action Imitation Learning (BAIL) first selects a number of high-performing state-action pairs from the batch dataset, then trains a policy with imitation learning. Our experiments show that BAIL’s performance is much higher than the other schemes, and is also computationally much faster than the batch Q-learning schemes. |
|
Striving for Simplicity and Performance in Off-Policy DRL: Output Normalization and Non-Uniform Sampling, Che Wang, Yanqiu Wu, Quan Vuong, Keith Ross. ICML 2020.
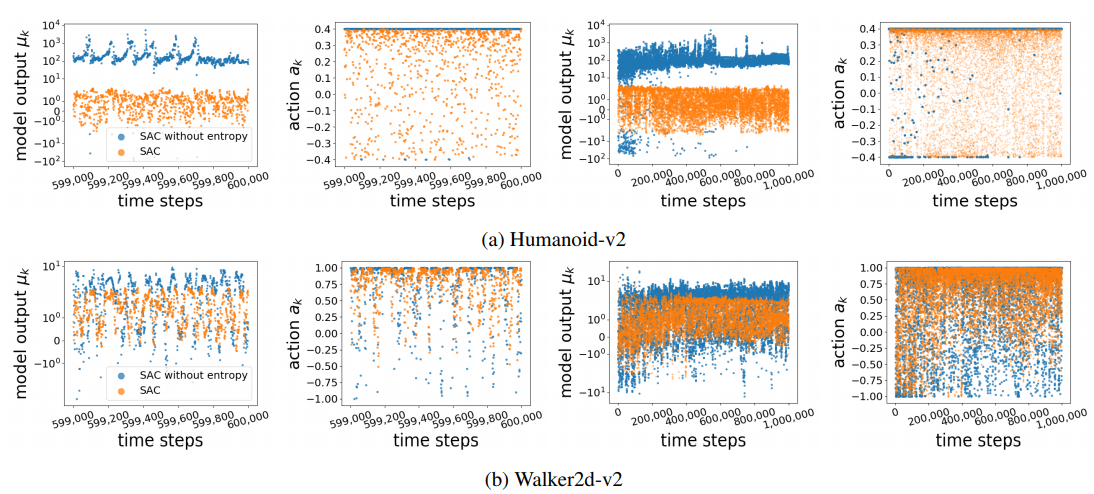
How exactly does entropy improve the performance of off-policy DRL methods? We first demonstrate that the entropy term in SAC addresses action saturation due to the bounded nature of the action spaces, with this insight, we propose a streamlined algorithm with a simple normalization scheme that can achieve the same performance without entropy. We then propose a simple non-uniform sampling method that boosts performance by emphasizing on recent experience. |

|
Portfolio Online Evolution In Starcraft. Che Wang, Pan Chen, Yuanda Li, Christoffer Holmgard, Julian Togelius. AIIDE 2016.
Research paper on a novice AI planning algorithm "Portfolio Online Evolution" in real-time strategy games, accepted for oral presentation in The Twelfth Annual AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE-16). An interview on this research from NYU Shanghai's student publication On Century Avenue can be found here: http://oncenturyavenue.org/2016/07/nyu-shanghais-watcher-wang-publishes-research-paper/ |

|
On the Convergence of the Monte Carlo Exploring Starts Algorithm for Reinforcement Learning, Che Wang, Keith Ross. Under review.
Establishing convergence for the classic MCES algorithm has been an open problem for more than 20 years. We present a proof on the convergence of the MCES algorithm for Optimal Policy Feed-Forward MDPs, which are MDPs whose states are not revisited within any episode for an optimal policy, making progress for this long-standing open problem in reinforcement learning. |
